HFrEF ICD 10 Coding The Ultimate Reference Guide

The core HFrEF ICD-10 codes are nested within the I50.2x category, which covers systolic (congestive) heart failure. For example, I50.22 is the go-to code for Chronic systolic heart failure, whereas I50.21 pinpoints an acute event. Mastering these codes is the first step to accurately identifying patients with heart failure with reduced ejection fraction in clinical charts and claims databases.
Your Quick Reference for HFrEF ICD-10 Codes

For data engineers, ETL developers, and clinical researchers, knowing the right HFrEF ICD-10 code is more than just a technicality; it's a fundamental requirement. Precise coding ensures patient cohorts are defined correctly, which is the bedrock of valid analytical outcomes and credible research. Even a slight misclassification can skew results and lead to flawed conclusions, making a deep understanding of these codes absolutely essential.
Clinically, heart failure with reduced ejection fraction is a specific type of systolic heart failure where the left ventricular ejection fraction drops to 40% or less. It's a major public health issue, impacting millions worldwide. In the United States alone, an estimated 6.7 million adults live with heart failure, and HFrEF accounts for about half of those cases-that's roughly 3.35 million patients. To better grasp how these diagnostic codes have evolved, you can find helpful insights on ICD-10 versus ICD-11 and their impact on healthcare data.
Primary HFrEF ICD-10-CM Codes at a Glance
For a quick summary, this table breaks down the core ICD-10-CM codes for HFrEF (Systolic Heart Failure) and their specific clinical meanings. It’s a handy reference for mapping documentation to the right code.
| ICD-10-CM Code | Official Description | Common Clinical Use Case |
|---|---|---|
| I50.21 | Acute systolic (congestive) heart failure | A patient presenting with a new, sudden onset of HFrEF symptoms. |
| I50.22 | Chronic systolic (congestive) heart failure | A patient with a long-term, stable diagnosis of HFrEF. |
| I50.23 | Acute on chronic systolic (congestive) heart failure | A patient with chronic HFrEF experiencing a sudden worsening of symptoms. |
These three codes-I50.21, I50.22, and I50.23-form the foundation for identifying the HFrEF patient population in most datasets. Understanding the distinction between acute, chronic, and acute-on-chronic presentations is the key to accurate cohort selection.
Tip: You can quickly verify these codes and explore their relationships to other terminologies using the Concept Lookup tool on OMOPHub.
Understanding The Clinical Nuances Of HFrEF
Before diving into the codes themselves, it's essential to have a firm grasp of the clinical picture. To work accurately with HFrEF ICD 10 codes, you need more than just a list; you need context. Heart Failure with reduced Ejection Fraction (HFrEF) is often called systolic heart failure for a reason-it's a problem with the heart's pumping phase.
Specifically, the left ventricle can no longer contract forcefully enough to push an adequate amount of blood out to the body. We measure this weakness using the Left Ventricular Ejection Fraction (LVEF), which is simply the percentage of blood that leaves the heart's main pumping chamber with each beat.
The clinical line in the sand for HFrEF is an LVEF of ≤40%. At this point, the heart is ejecting 40% or less of the blood in the ventricle, failing to keep up with the body's needs. This condition doesn't happen overnight; it's typically the end result of long-term damage from things like coronary artery disease, a history of heart attacks, or untreated hypertension.
Distinguishing HFrEF from HFpEF
One of the most common-and critical-mistakes in data analysis is confusing HFrEF with its counterpart, Heart Failure with preserved Ejection Fraction (HFpEF). While the symptoms can look identical to a patient, the underlying problems are fundamentally different. Getting this wrong can completely skew your results.
- HFrEF (Systolic Failure): Think of a weak, stretched-out pump. The left ventricle is often enlarged but lacks the muscle strength to contract effectively. The core issue is the squeeze.
- HFpEF (Diastolic Failure): Here, the pump is strong but stiff. The left ventricle can't relax and fill up properly between beats, even though the LVEF is normal (usually >50%). The core issue is relaxation and filling.
This isn't just academic. Lumping these two distinct patient groups together is like mixing apples and oranges; you're blending two completely different disease processes, which will invalidate any clinical or research findings you produce.
Mapping HFrEF ICD-10 Codes To OMOP And SNOMED
To conduct any kind of robust, standardized analysis, you first need to get your source data speaking a common language. For heart failure research, this means translating an HFrEF ICD 10 code into its corresponding OMOP Standard Concept. This is more than just a technical step; it's the foundation for creating patient cohorts that are reliable and truly interoperable.
This standardization is precisely what lets researchers confidently combine data from different healthcare systems, or even different countries, knowing they're all looking at the same clinical condition.
In the OMOP Common Data Model (CDM), the destination for these mappings is almost always SNOMED CT, a massive and meticulously structured clinical healthcare terminology. Essentially, when you map an ICD-10-CM code, you are tethering a billing code to a universally understood clinical concept.
The Standardization Process
The jump from the older, less specific ICD-9 codes to the modern ICD-10 system, with its 74,000-plus diagnosis options, gave us a much finer level of detail. Of course, the World Health Organization continually updates these classifications, which creates a maintenance challenge.
This is where automated tools become indispensable. For developers working with OMOP, using something like the OMOPHub REST APIs in their Python or R ETL pipelines means they don't have to manage local vocabulary databases. The APIs handle the version syncing and map everything to standards like SNOMED automatically, which is a huge benefit for anyone needing to keep their OMOP CDM instance current.
Take the ICD-10-CM code I50.22 (Chronic systolic (congestive) heart failure). In the real world, this code doesn't exist in a vacuum. Within the OMOP vocabulary tables, it's explicitly linked through a 'Maps to' relationship to a specific SNOMED CT concept. This connection locks in its precise clinical meaning, paving the way for more powerful and accurate queries across datasets that may have started with entirely different coding systems. If you're interested in the nuts and bolts of this process, we have a complete guide on semantic mapping strategies.
Key Takeaway: Standardization isn't just a data cleaning task. It's the critical process that ensures your HFrEF cohort definition is consistent and clinically sound, no matter where the data came from. It's what makes large-scale, multi-site research not just possible, but trustworthy.
HFrEF ICD-10 to OMOP Standard Concept Mapping Examples
The table below provides a few clear examples of how specific ICD-10-CM codes for Heart Failure with reduced Ejection Fraction are mapped to their standard SNOMED CT concept counterparts in the OMOP CDM. This illustrates the direct link between a source code used for billing and its corresponding clinical concept used for analytics.
| ICD-10-CM Code | Maps to Relationship | Standard Concept ID (SNOMED) | Standard Concept Name |
|---|---|---|---|
| I50.21 | Maps to | 428351000124103 | Acute systolic heart failure |
| I50.22 | Maps to | 429302005 | Chronic systolic heart failure |
| I50.23 | Maps to | 428981000124104 | Acute on chronic systolic heart failure |
As you can see, the 'Maps to' relationship creates an unambiguous bridge, ensuring that analyses built on these standard concepts are based on a consistent clinical definition.
Automating HFrEF Concept Lookups With Code
While looking up codes manually is fine for one-off checks, it just doesn't scale. For any serious data pipeline or analytical tool, automating the mapping of an HFrEF ICD-10 code to its standard OMOP concept is a necessity. A programmatic approach is the only way to eliminate manual errors, enforce consistency across datasets, and embed vocabulary services right into your ETL workflows.
By using the OMOPHub SDKs for Python and R, your team can handle these lookups in real-time. This completely sidesteps the headache of hosting and maintaining your own local vocabulary databases. It not only speeds up development but also ensures your mappings are always synced with the latest official ATHENA vocabulary releases.
Programmatic Lookups in Python and R
Let's walk through a practical example: finding the Standard Concept ID for the ICD-10-CM code I50.22 (Chronic systolic heart failure). The logic is pretty straightforward: authenticate with an API key, call the concept lookup function, and then filter the results to find the crucial 'Maps to' relationship that links it to the correct SNOMED concept.
If you're new to this, the whole point is to create a repeatable, automated path from a source code to a standard concept. This is fundamental for interoperability.
This diagram shows that flow in action-from a source ICD-10 code, through the OMOP CDM's mapping tables, and finally arriving at its standardized SNOMED CT destination.
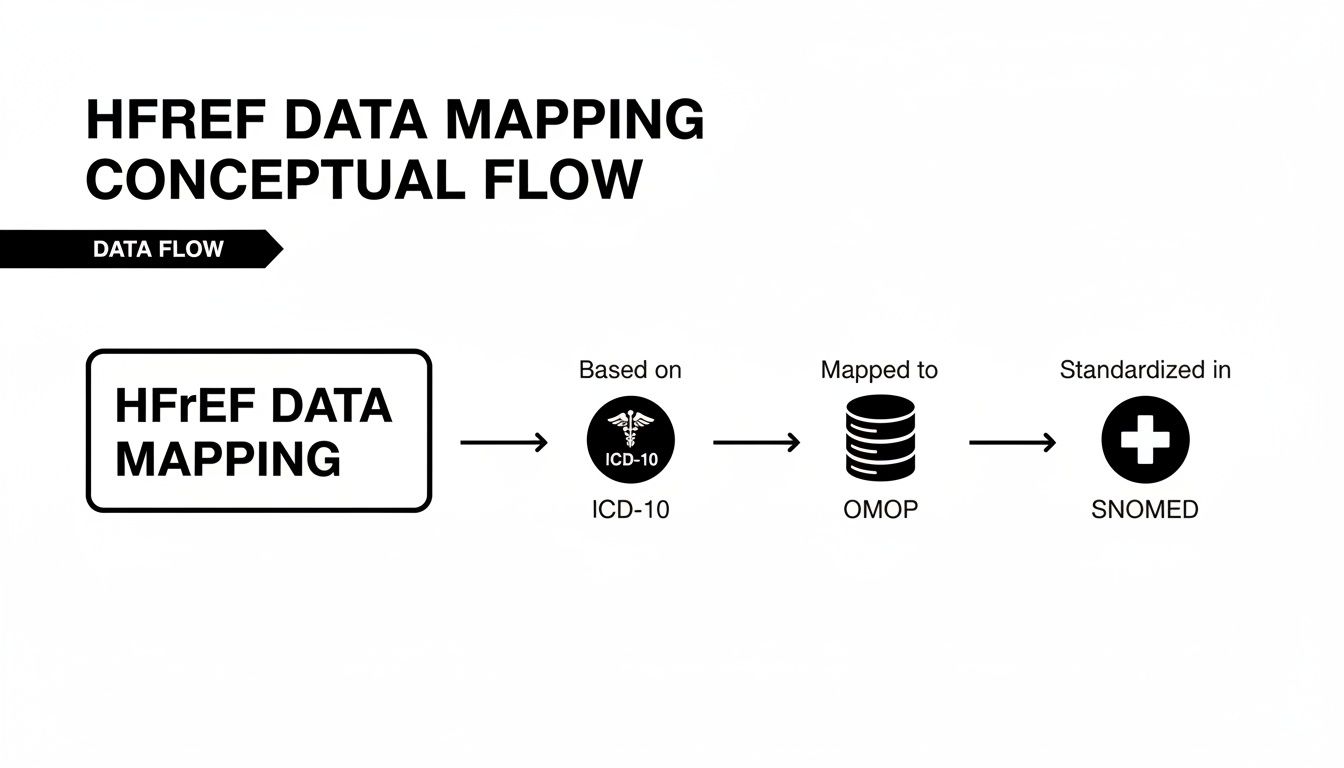
It’s this standardization process that makes multi-site research and large-scale analytics possible.
Python SDK Example
Here’s a simple Python script using the omophub library to find the SNOMED CT concept that I50.22 maps to. You can find more examples like this in the official OMOPHub documentation.
from omophub.client import Client
# Initialize client with your API key
client = Client(api_key="YOUR_API_KEY")
# Find the concept for I50.22
concept_details = client.concepts.lookup(
concept_code="I50.22",
vocabulary_id=["ICD10CM"]
)
# Find the 'Maps to' relationship
for rel in concept_details.relationships:
if rel.relationship_id == "Maps to":
print(f"ICD-10-CM 'I50.22' maps to SNOMED Concept ID: {rel.concept_id_2}")
# Expected Output: ICD-10-CM 'I50.22' maps to SNOMED Concept ID: 429302005
R SDK Example
And for the R users out there, the omophub package accomplishes the same thing with a similar approach.
library(omophub)
# Configure your API key
Sys.setenv(OMOPHUB_API_KEY = "YOUR_API_KEY")
# Find the concept for I50.22
concept_details <- concepts_lookup(
concept_code = "I50.22",
vocabulary_id = c("ICD10CM")
)
# Filter for the 'Maps to' relationship
maps_to_rel <- subset(concept_details$relationships, relationship_id == "Maps to")
print(paste("ICD-10-CM 'I50.22' maps to SNOMED Concept ID:", maps_to_rel$concept_id_2))
# Expected Output: "ICD-10-CM 'I50.22' maps to SNOMED Concept ID: 429302005"
Tips for Effective API Usage
To really get the most out of these tools in a production environment, it pays to follow a few best practices.
- Batch Your Requests: If you're churning through thousands of codes, don't send one API call per code. Batching your lookups into larger requests is far more efficient and dramatically cuts down on network overhead.
- Cache Frequent Lookups: Your data will have high-frequency codes. Caching the mapping results for these common codes locally will prevent redundant API calls and make your ETL jobs run much faster.
- Handle Non-Standard Codes: You will inevitably encounter source codes that don't have a clean, direct 'Maps to' relationship. Your code needs to anticipate this-build in logic to handle these cases gracefully and log them for manual review.
By bringing this kind of automation into your workflow, you enable your team to build more robust, accurate, and maintainable healthcare data systems. For anyone wanting to get more comfortable with SNOMED itself, I'd recommend checking out our guide on using a SNOMED CT browser to explore its hierarchy.
Building High-Fidelity HFrEF Patient Cohorts

When it comes to research, pulling a list of patients based on an HFrEF ICD 10 code is just the starting point. To build a truly research-grade cohort, you need to go much deeper. It's a process of layering in additional clinical data to confirm the diagnosis, weed out false positives, and ensure the final group is as accurate and reliable as possible.
This really boils down to creating strict, well-defined inclusion and exclusion criteria. The aim is to craft a precise definition that genuinely reflects the patient's clinical state. As you think about the data infrastructure for this, it's worth noting that flexible systems like nonrelational databases can be a great fit for managing the variety of data types you'll be handling.
Refining Cohorts with Clinical Data
Moving from a rough list of codes to a precise cohort means integrating multiple data streams. This strategy adds layers of clinical validation that a single diagnosis code, on its own, simply can't offer.
-
Inclusion/Exclusion Logic: First, define your rules. For instance, you’ll want to actively exclude patients with conditions that could muddy the waters, like a prior heart transplant (ICD-10-CM code Z94.1) or the presence of a left ventricular assist device (LVAD). To get a better feel for this, you can review a detailed inclusion criteria example to see how these rules are put together in practice.
-
Lab Data Confirmation: The hallmark of HFrEF is a reduced Left Ventricular Ejection Fraction (LVEF). This is where lab data becomes indispensable. You should be looking for specific LOINC codes tied to LVEF measurements (like LOINC
22120-3) and then filter for values that are ≤40%. This step gives you quantitative, hard evidence of the HFrEF diagnosis. -
Procedural Code Corroboration: Don't overlook procedure codes. They add another powerful layer of evidence. Codes for procedures like cardiac catheterization or echocardiograms frequently show up in a patient's record around the time of an HFrEF diagnosis, acting as strong corroborating events.
The Importance of Temporality
The sequence and timing of these clinical events are absolutely critical. A valid HFrEF diagnosis needs to make sense within the patient's overall timeline.
You have to ensure that any confirmatory lab values or procedures happened within a clinically relevant window relative to the initial HFrEF ICD 10 diagnosis. This temporal analysis is key to avoiding the inclusion of old, resolved conditions and ultimately solidifies the accuracy and integrity of your cohort.
Avoiding Common HFrEF Data And Coding Pitfalls
When it comes to clinical analytics, the quality of your insights is only as good as the quality of your data. This is especially true when working with the HFrEF ICD 10 codeset, where a few common mistakes can easily corrupt a dataset and undermine your findings. Recognizing these potential issues is the critical first step in building the kind of robust validation checks that every ETL process and analytical workflow needs.
Common Coding Blunders
One of the most frequent and serious errors is mixing up the codes for HFrEF (I50.2x) with those for Heart Failure with preserved Ejection Fraction, or HFpEF (I50.3x). While their clinical symptoms can sometimes look similar, they are fundamentally different conditions. Lumping them together is a major classification mistake that will completely destroy the specificity of your HFrEF patient cohort.
Another pitfall to watch for is the overuse or misinterpretation of I50.9, Heart failure, unspecified. This code is a red flag. Because it tells you nothing about the patient's systolic function, it should almost always be excluded from a specific HFrEF cohort. Including it just adds ambiguity and noise, making any subsequent analysis unreliable.
Proactive Data Quality Tips
To get ahead of these common coding problems, you need a strategy to improve data quality right from the source. Here are a few practical tips from the field:
- Validate with LVEF Data: Don't just trust the diagnosis code. Whenever you can, cross-reference it with actual clinical data. A true HFrEF diagnosis must be backed by a Left Ventricular Ejection Fraction (LVEF) value of ≤40%.
- Account for Code Evolution: Remember that coding standards and billing practices are not static. A patient's record is a timeline, so you have to account for older, superseded diagnoses to get an accurate picture of their current clinical status.
- Look Beyond Billing Codes: Billing data is often incomplete. For a more robust validation, you might need to pull in data from clinical notes using Natural Language Processing (NLP) to find the nuanced details that structured codes miss.
The stakes here are incredibly high, both clinically and financially. HFrEF, which falls under ICD-10 codes I50.2-I50.4, is a huge driver of healthcare expenses, responsible for an estimated 25% of Medicare spending in cardiology. Getting the coding right isn't just an academic exercise; it has a massive real-world impact. You can dig deeper into the financial side of things by reviewing updates on ICD-10-CM updates and revenue strategy to see just how crucial precise coding truly is.
Answering Your HFrEF Coding Questions
When you're deep in the data, questions about HFrEF coding are bound to come up. It's a nuanced area. Let's tackle some of the most common issues data teams face when working with HFrEF ICD-10 codes and building cohorts for analysis.
The Big Difference: I50.2x vs. I50.3x
One of the first hurdles is distinguishing between the I50.2x and I50.3x code families. It's actually quite straightforward once you know the clinical distinction.
Think of it this way: I50.2x codes are for Systolic heart failure (HFrEF). This is the classic "pumping problem" where the left ventricle can't contract effectively. In contrast, I50.3x codes point to Diastolic heart failure (HFpEF), a "filling problem" where the ventricle is stiff and can't relax properly, even though the pumping action itself might seem fine.
Why Acute on Chronic Codes Matter
Pay close attention to I50.23 (Acute on chronic systolic heart failure). This isn't just another code; it's a critical flag in your data. It signals a major worsening of a long-term condition, an event that almost always leads to hospitalization and a spike in healthcare resource use. For any kind of risk modeling or cost analysis, I50.23 is a must-have.
Building a Clean HFrEF Cohort
Here’s a common question: should you include the unspecified heart failure code, I50.9, in an HFrEF cohort? My advice is a firm no.
Including I50.9 muddies the waters significantly. It doesn't tell you anything about systolic dysfunction, which is the defining characteristic of HFrEF. If your goal is a high-precision, reliable cohort, you need to stick strictly to the I50.2x code family. Anything else introduces too much noise.
Finding the Right SNOMED Mappings
Mapping from ICD-10 to a standardized vocabulary like SNOMED is essential for robust analytics. Instead of doing this manually, you can use the OMOPHub SDKs for Python or R to do the heavy lifting.
These tools let you programmatically find the 'Maps to' relationship for any HFrEF ICD-10 code. This automates a huge part of the data standardization process, ensuring your analysis is built on accurate and interoperable data from the start.
Tired of managing vocabulary databases and want to speed up your data workflows? With OMOPHub, you can plug standardized clinical terminologies directly into your applications through a powerful REST API. Start building more accurate and scalable healthcare analytics today.


