A Practical Guide to Mastering SDTM for Clinical Data

The Study Data Tabulation Model, or SDTM, is the rulebook for organizing clinical trial data before sending it off to regulatory bodies. Think of it as a universal translator for clinical research. It ensures that data collected in a trial in Germany looks exactly the same as data from a trial in Japan, making it far easier for agencies like the FDA to review, analyze, and ultimately approve new treatments.
This isn't just a "nice-to-have." For modern clinical research, it's a mandatory part of the process.
Understanding the Role of SDTM in Clinical Research

Before standards like SDTM became widespread, the world of clinical data was a bit like the Wild West. Imagine trying to build a single, coherent puzzle from pieces made by a dozen different manufacturers-none of them fit together.
Each research sponsor had its own proprietary way of collecting and organizing data. This forced regulatory reviewers to waste precious time just trying to figure out the structure of each dataset. They were spending more time being data archaeologists than scientific reviewers.
The Clinical Data Interchange Standards Consortium (CDISC) stepped in to solve this chaos by creating SDTM. It provides a standard blueprint that spells out precisely how every piece of clinical trial data should be structured.
The Power of a Standardized Blueprint
SDTM works by organizing data into specific "domains," which are just collections of observations of a particular type. For instance, all patient demographic information goes into the Demographics (DM) domain. Any adverse events are logged in the Adverse Events (AE) domain.
This simple, consistent organization brings some huge benefits to the table:
- Faster Review Cycles: When regulators get data in a format they already know, they can plug it directly into their standard analysis tools. This shaves a significant amount of time off the review process.
- Better Data Quality: A rigid structure makes it much easier to programmatically check for errors and inconsistencies, which naturally leads to a higher-quality submission package.
- True "Apples-to-Apples" Comparisons: By forcing all studies to play by the same rules, SDTM makes it possible to compare and aggregate data across different trials-a task that used to be nearly impossible.
Why SDTM Is Non-Negotiable Today
At this point, SDTM isn't optional; it's the foundation of modern clinical data submission. Major regulatory bodies, including the FDA in the United States and the PMDA in Japan, mandate its use.
The standard dictates everything from domain names and their structure to the specific variable names used within them. This level of detail ensures every single data point can be quickly identified and interpreted, which is exactly what you want when a new therapy is under review. If you want to dive deeper, you can learn more about how SDTM streamlines regulatory submissions and get a complete overview.
Key Takeaway: SDTM is more than just a data format. It’s a complete framework that brings order and predictability to the incredibly complex world of clinical trial data. If you work in clinical data management, biostatistics, or regulatory affairs, fluency in SDTM is essential.
For the data engineers and developers tasked with building the pipelines, this standardization is a game-changer. It provides a clear, unambiguous target for any ETL (Extract, Transform, Load) process. You're no longer guessing how to map raw data into a submission-ready format. Instead, you have a repeatable, compliant workflow-the key to building any scalable data operation.
Understanding the Core Components of SDTM

To really get a handle on SDTM, you have to first appreciate how it organizes the mountains of data from a clinical trial. Instead of one gigantic, unwieldy file, SDTM smartly breaks everything down into logical, bite-sized pieces called domains.
Think of a clinical trial dataset as a massive library. Each SDTM domain is like a specific section-"Cardiology," "Oncology," or "Patient Diaries"-that holds a particular type of information. This isn't random; it's all built on a simple but powerful classification system that sorts every bit of data into one of three General Observation Classes. These classes are the conceptual backbone of the whole framework.
Getting your head around these classes is the first real step to mastering the SDTM landscape. They give you a high-level map, showing you where to find what you're looking for and how all the different pieces fit together.
The Three General Observation Classes
At its heart, SDTM categorizes every piece of study data based on the nature of the observation. This is a brilliant way to simplify the structure and ensure that similar information is always found in the same place, no matter the specific disease or drug being studied.
Here’s how the three classes break down:
- Interventions: This class is all about things done to the subject. It captures any treatments or therapies given as part of the trial protocol, from the study drug itself to concomitant medications or other substances.
- Events: This class records things that happen to a subject during the trial. These can be planned occurrences, like finishing a study phase, or unplanned incidents, like an adverse event.
- Findings: This is where you'll find the results of planned assessments. It contains all the hard data from lab tests, vital signs, ECGs, and patient-reported outcomes from questionnaires.
This classification system is a fantastic mental model for navigating trial data. When you need to track down a specific data point, you can start by simply asking: was this done to the subject, did it happen to the subject, or was it a result of a test on the subject?
Pro Tip: When you're planning an ETL process, your first move should be to map your raw source data to one of these three general observation classes. This initial sorting makes the more detailed mapping to specific SDTM domains much easier and keeps your data flow logical and compliant from the get-go.
Special Purpose and Trial Design Domains
Beyond the observation classes that organize subject-level data, the SDTM model includes other essential datasets that provide crucial context. After all, the trial's structure is just as important as the patient data.
SDTM uses a few special-purpose domains to house this foundational information. These include Demographics (DM), Comments (CO), Subject Elements (SE), and Subject Visits (SV). On top of that, you have trial design datasets like Trial Summary (TS) and Trial Arms (TA) that describe the very architecture of the study. If you want to dig deeper into this structure, you can review this overview of the SDTM framework.
These datasets are non-negotiable for understanding the observation data. The Demographics (DM) domain, for instance, is the cornerstone of any SDTM submission, holding one unmovable record per subject with key information like age, sex, and race.
To give you a better feel for this, the table below breaks down some of the most common and critical domains you'll encounter day-to-day.
Key SDTM General Observation and Special Purpose Domains
| Domain Code | Domain Name | Observation Class | Description |
|---|---|---|---|
| DM | Demographics | Special Purpose | Contains fundamental subject characteristics like age, sex, race, and ethnicity. |
| AE | Adverse Events | Events | Records all adverse events experienced by subjects during the study. |
| CM | Concomitant Meds | Interventions | Lists all medications taken by subjects other than the investigational study drug. |
| EX | Exposure | Interventions | Details the dosage and administration of the study drug for each subject. |
| VS | Vital Signs | Findings | Captures standard clinical measurements like blood pressure, heart rate, and temperature. |
| LB | Laboratory Test Results | Findings | Stores the results from all laboratory tests, such as blood chemistry and hematology. |
| TS | Trial Summary | Trial Design | Provides key parameters about the trial design itself, like study objectives and criteria. |
Familiarizing yourself with these core domains is essential. They represent the most frequently used buckets for clinical data and form the foundation of nearly every SDTM submission package you'll ever work with.
Getting Your Hands Dirty: Practical SDTM Implementation and Common Pitfalls
Knowing the SDTM rulebook is one thing; actually applying it to messy, real-world clinical data is a whole different ball game. This is where theory meets reality, and where many projects, unfortunately, go off the rails. Success isn't about fixing mistakes after the fact-it's about building a solid process from the ground up to prevent them in the first place.
Most teams stumble over the same predictable hurdles. These aren't usually exotic technical bugs, but rather fundamental gaps in planning, misinterpretations of the rules, or fuzzy logic in assigning data to the right place. Spotting these traps early is half the battle.
Navigating the Key Implementation Challenges
Let's break down the most common mistakes I see time and time again. Getting these right from the start will save you a world of headaches down the road.
Here are the big three:
- Inconsistent Variable Naming: Your source data is a mess. The same concept might be called "WT," "Weight," or "Subj. Weight" across different files.
- How to Fix It: Don't even think about starting the ETL process until you've created a comprehensive data dictionary and a detailed mapping spec. This document becomes your project's Rosetta Stone-the single source of truth that dictates exactly how every source field maps to its SDTM target.
- Incorrect Domain Assignments: This one is incredibly common. For example, a team might see a lab test that measures a drug’s effect and instinctively want to put it in a custom "efficacy" domain. That’s wrong. It belongs in the Laboratory Test Results (LB) domain.
- How to Fix It: Always, always go back to the three general observation classes: Interventions, Events, and Findings. Ask yourself: Was this done to the subject? Did this happen to the subject? Or was this a measurement from the subject? That simple logic will almost always point you to the correct standard domain.
- Wrestling with Controlled Terminology: Many SDTM variables don't allow free text; they demand you use a specific term from a predefined list (controlled terminology). Trying to map messy, free-text source data to these strict, standardized terms can feel like an impossible task.
- How to Fix It: You need to integrate a robust vocabulary service into your workflow early on. Tools that give you programmatic access to standardized vocabularies are non-negotiable for accurately mapping clinical terms. This is a critical step not just for SDTM, but for any future mapping to models like OMOP.
Building a Strong Governance Foundation
A successful SDTM project starts long before anyone writes a single line of code. The most critical step is establishing a clear data governance plan. Think of it as the constitution for your project-it defines roles, responsibilities, and the rules for how data is handled from start to finish.
Your governance plan needs to map out the entire data flow, from the moment you receive the raw data to the final, validated SDTM datasets. It must spell out how to handle discrepancies, manage updates to controlled terminologies, and version your mapping specifications. Without this framework, teams end up working in silos, which inevitably leads to rework and inconsistencies that are painful and expensive to fix later on.
A great way to enforce these rules is to integrate a validation tool like Pinnacle 21 into your development cycle from day one. Run it early and often. This helps you catch errors programmatically before they get baked into your datasets.
Pro Tip: Your best defense against chaos is documentation. Every single mapping decision, every justifiable deviation from the standard, and every data cleaning rule needs to be recorded in a Study Data Reviewer's Guide (SDRG). If you need pointers on creating clear, effective documentation for data pipelines, check out resources like the OMOPHub documentation for practical examples.
Ultimately, it all comes down to being proactive. A sharp focus on planning, solid governance, and early validation can turn the complex, often frustrating task of SDTM implementation into a predictable and repeatable process. This doesn't just get you past regulatory hurdles; it builds a foundation of high-quality data that you can trust for all your downstream analysis and reporting.
And for teams building these pipelines programmatically, SDKs for popular languages like the OMOPHub Python SDK or the OMOPHub R SDK can give you a massive head start.
Automating SDTM Mapping with Modern Tools
Anyone who has mapped raw clinical data to the SDTM format knows it can be a painstaking, manual grind. This traditional approach has been the industry standard for years, but it’s a major bottleneck in the submission pipeline. It’s slow, it consumes a ton of resources, and worst of all, it’s prone to human error and inconsistent interpretations that can put data quality at risk.
The problem is only getting bigger. As clinical trials become more complex and the sheer volume of data explodes, relying on manual mapping just isn't sustainable. The time it takes and the risk of errors can easily delay submissions and drive up project costs. This reality has forced the industry to look for smarter, more scalable ways to get the job done.
The Rise of AI and Machine Learning in SDTM
This is where modern technology, especially artificial intelligence (AI) and machine learning (ML), is starting to make a real difference. Instead of a data manager manually poring over every single data point, AI-powered tools can now automate huge chunks of the mapping workflow, predicting the right domain and variable with remarkable accuracy.
How do they do it? Most of these tools rely on supervised learning. You train a model on a massive repository of historical, successfully mapped SDTM datasets. Over time, the model learns the complex patterns, rules, and relationships between all kinds of source data and their correct SDTM destinations.
This completely changes the job description for the human data mapper. Their role shifts from doing tedious, repetitive tasks to focusing their expertise where it truly matters-on the tricky, ambiguous cases that require a nuanced human judgment call.
How Automated Mapping Works in Practice
At their core, these automated systems are all about predictive modeling and confidence scoring. When you feed new source data into a trained model, it analyzes everything from variable names and data types to other metadata to suggest the most likely SDTM domain and variable.
One of the most powerful features here is the use of confidence thresholds. Think of it as a dial you can turn to balance precision (how accurate the predictions are) and recall (how many mappings the model tries to predict).
- High Confidence Mappings: Any prediction that scores above a set threshold, say 95% confidence, can be automatically approved. This alone can slash manual review time.
- Medium Confidence Mappings: Predictions that fall into a middle ground are flagged for a human to review, pointing the expert directly to the areas that need a second look.
- Low Confidence Mappings: Anything below the threshold is left for manual mapping from scratch. This ensures that the most complex or unusual data points get the full attention they deserve.
The results speak for themselves. Early machine learning models hit baseline accuracy rates of 75.1% for domain predictions and 83.9% for variable predictions. But by layering in confidence thresholds and other decision rules, performance jumped to 96.6% for domains and 86.9% for variables.
Key Takeaway: Automation isn't here to replace human experts. It's here to supercharge them. By taking over the high-volume, repetitive work, these tools free up clinical data specialists to solve the hard problems, boost overall data quality, and get submissions out the door faster.
As organizations look for new ways to improve efficiency, exploring options like integrating LLMs for SDTM automation is becoming a practical next step. If you're curious about the broader applications of this technology, our guide on semantic mapping is a great place to start. Ultimately, these tools offer a clear path toward creating faster, more consistent, and higher-quality SDTM datasets.
Bridging SDTM and OMOP CDM for Broader Insights
While SDTM is the gold standard for submitting clinical trial data, its real power is often unleashed when you combine it with real-world data (RWD). That's where the Observational Medical Outcomes Partnership (OMOP) Common Data Model (CDM) comes in.
Mapping your SDTM datasets to OMOP CDM effectively builds a bridge between the clean, structured world of clinical trials and the often messy, diverse data from routine clinical practice. This connection is what lets researchers conduct massive, powerful analyses that simply weren't possible before. It opens the door to better cohort discovery, long-term safety monitoring, and more robust comparative effectiveness research.
The process itself is a careful translation. You're taking the domain-and-variable structure of SDTM and re-shaping it into OMOP’s person-centric architecture. Getting this right requires a solid grasp of both models to make sure the data’s meaning isn’t lost in translation during the ETL (Extract, Transform, Load) workflow.
This flowchart shows how the industry is moving away from purely manual mapping efforts toward more sophisticated, automated systems.
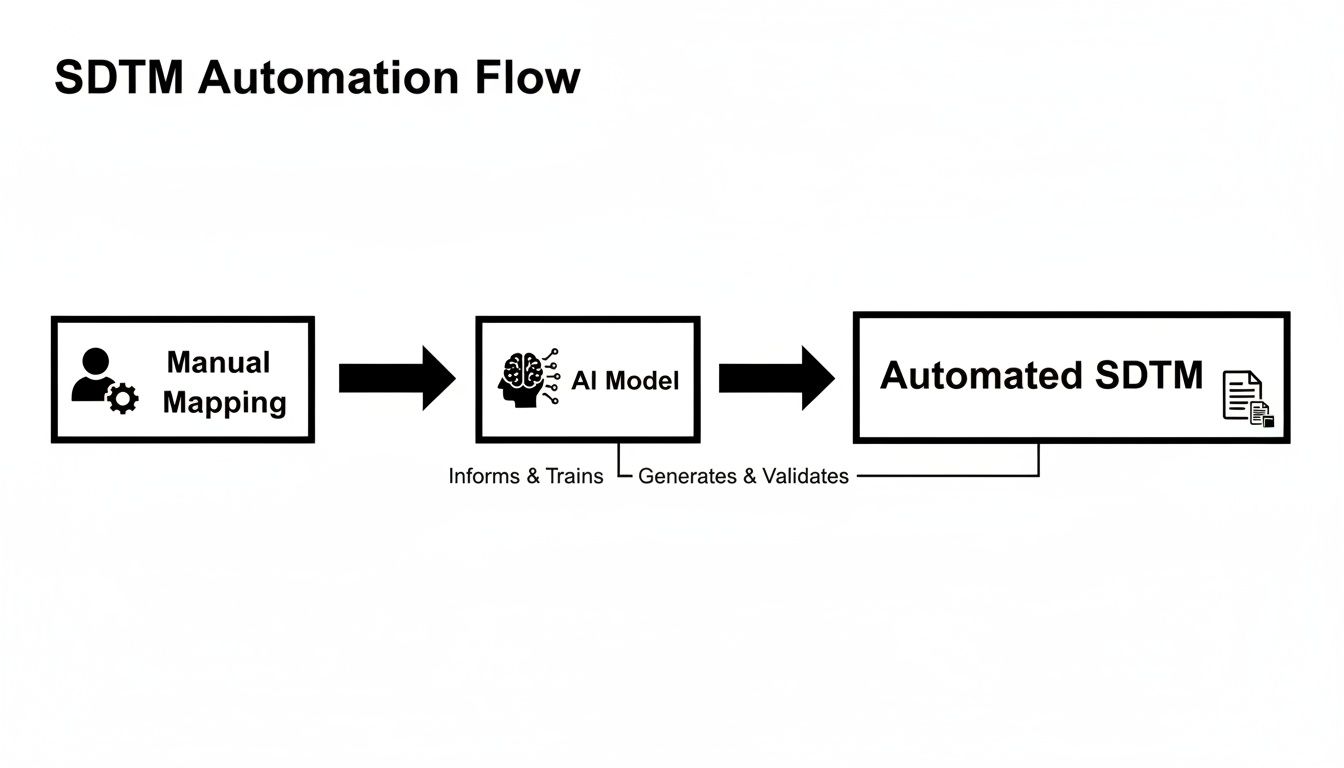
The progression from hand-cranked processes to AI-driven automation really captures the push for more efficient and scalable data transformation.
The Step-by-Step Mapping Workflow
Getting from SDTM to OMOP is a methodical journey. The key is to start by identifying the most critical SDTM domains and then figuring out where they logically belong inside the OMOP CDM.
- Identify Key SDTM Domains: You don't have to boil the ocean all at once. Start with the domains that carry the most weight, which are typically Demographics (DM), Adverse Events (AE), Laboratory Test Results (LB), Exposure (EX), and Concomitant Medications (CM).
- Map to Primary OMOP Tables: Every SDTM domain has a natural home in OMOP. For example, the DM domain, with its one-record-per-subject structure, maps cleanly to OMOP's PERSON table.
- Handle Observation Data: Here’s where most of the work happens. You need to map the records from SDTM's various observation-based domains (like Events and Findings) to the right clinical event tables in OMOP. Think CONDITION_OCCURRENCE, MEASUREMENT, or DRUG_EXPOSURE.
- Standardize with Vocabularies: This is the most critical step of all. While both models use standardized terms, OMOP enforces this with a vengeance through its vocabulary tables. You have to map the source terms found in SDTM variables-like
AETERMfor adverse events orLBTESTfor labs-to standard concept IDs from vocabularies like SNOMED CT or LOINC.
This harmonization ensures that a "myocardial infarction" recorded in a trial's AE domain gets stored with the exact same concept ID as a heart attack documented in someone's electronic health record. For a deeper look at the OMOP structure, check out our comprehensive guide on the OMOP data model.
A well-executed SDTM to OMOP ETL pipeline doesn’t just move data; it translates it into a common scientific language. This is what allows researchers to ask bigger questions and generate stronger evidence by weaving together insights from both clinical trials and routine clinical practice.
Mapping SDTM Domains to OMOP CDM Tables
To make the mapping logic clearer, it helps to see the connections laid out. The table below is a high-level guide that shows how some of the most common SDTM domains find their place within the OMOP structure.
| SDTM Domain | Description | Primary OMOP CDM Table | Key Mapped Concepts |
|---|---|---|---|
| DM | Demographics | PERSON | Subject's birth date, sex, race, and ethnicity. |
| AE | Adverse Events | CONDITION_OCCURRENCE | The adverse event term (AETERM) is mapped to a SNOMED CT condition concept. |
| LB | Lab Test Results | MEASUREMENT | The lab test name (LBTEST) is mapped to a LOINC concept; the result is stored with its unit. |
| EX | Exposure | DRUG_EXPOSURE | Details of the study drug, including dose and frequency, are mapped to RxNorm concepts. |
| CM | Concomitant Medications | DRUG_EXPOSURE | Medications taken alongside the study drug are also mapped to RxNorm concepts. |
This gives you a starting point for thinking about how the data flows from a trial-centric format to a patient-centric one.
Tools and Recommendations
Actually performing the mapping, especially the vocabulary piece, requires the right tools. Trying to do this manually is a recipe for errors and wasted time.
Automate Vocabulary Mapping with SDKs
For anyone building a scalable and repeatable ETL pipeline, programmatically mapping source terms to standard concept IDs is a must. Modern tools like the OMOPHub SDKs are designed to make this much easier by giving you direct API access to OHDSI's ATHENA vocabularies.
Instead of wrestling with a massive local vocabulary database, a developer can use a few lines of code to look up the correct standard concept for any given term. This not only speeds things up but also ensures your mappings are consistent and always current with the latest vocabulary releases.
Tip for Developers: Use an SDK to automate your vocabulary lookups. For instance, when mapping the LB domain, you can write a simple script that loops through each unique
LBTESTCDvalue, searches for a matching LOINC concept via the SDK, and then populates your targetMEASUREMENTtable with the correctconcept_id. This approach is far more reliable and efficient than manual cross-referencing. For a practical example, see the vocabulary mapping documentation which provides Python and R code snippets using the OMOPHub SDKs.
Ensuring Data Quality and Regulatory Compliance
Getting your data into SDTM format is a huge step, but it's not the finish line. Before you can even think about submitting to a regulatory agency, you have to put your datasets through a rigorous validation process.
Think of it like getting a home ready for sale. You might think it looks great, but a professional home inspector is going to check the foundation, wiring, and plumbing against a strict building code. In the clinical data world, that "inspection" means checking your datasets against a comprehensive set of CDISC rules to prove they're submission-ready.
The Role of Validation Tools
To handle this critical step, the industry has standardized on specific validation tools. The most well-known is Pinnacle 21 Community, which essentially acts as an automated auditor for your data.
These tools programmatically check your entire SDTM package against hundreds of validation rules published by CDISC and regulatory bodies like the FDA. The checks fall into a few key buckets:
- Conformance Rules: Does your dataset structure actually follow the SDTM Implementation Guide? Are all the required variables there and in the right format?
- Consistency Checks: Does the data make sense across different domains? For instance, if a subject has a record in the exposure (EX) domain, they absolutely must have a corresponding record in the demographics (DM) domain.
- Controlled Terminology: For variables that need standardized terms-like adverse event severity-did you use the exact, approved vocabulary from the NCI thesaurus?
The output is a detailed validation report that becomes your to-do list for fixing any issues. This report flags every error, warning, and notice, letting your team tackle problems systematically before the final submission. Learning to read and respond to these reports is a fundamental skill for any clinical data manager or programmer.
Interpreting and Remediating Common Errors
When you get that validation report back, you need to know how to prioritize. Errors are the big ones-they are typically showstoppers that must be fixed. Warnings, on the other hand, often just need a solid explanation documented in the Study Data Reviewer's Guide (SDRG).
Some of the most common issues you'll run into include:
- Missing Required Variables: A domain is missing a variable that CDISC considers mandatory.
- Incorrect ISO 8601 Formatting: Dates and times are messy and don't stick to the required
YYYY-MM-DDTHH:MM:SSformat. - Controlled Terminology Mismatches: You used a term like "Mild" when the required codelist term was actually "MILD" in all caps.
Key Takeaway: Don't treat validation as a one-and-done checklist item at the very end. The best practice is to run validation checks early and often throughout your ETL development. This iterative approach helps you catch small problems before they become massive, time-consuming headaches later on.
Beyond Validation: Broader Governance Principles
True compliance goes deeper than just passing a validation check. It’s about having a solid data governance and security framework in place.
Protecting sensitive clinical trial data means implementing features like immutable audit trails to track every single change and end-to-end encryption to secure data whether it's sitting on a server or moving across a network. These measures are what guarantee data integrity all the way from collection to submission. If you're curious about how these principles extend into other areas of research, our article on real-world evidence offers some great related insights.
To take your data quality efforts even further, it's worth exploring modern best practices. Adopting efficient and reliable methods like test automation in healthcare can make a significant difference. Ultimately, a proactive approach to quality and compliance is what makes your data not just correct, but truly trustworthy.
Common Questions About SDTM
Let's wrap up by tackling some of the questions that always seem to pop up when people start working with SDTM. Getting these straight can save a lot of headaches down the road.
What’s the Real Difference Between SDTM and ADaM?
It helps to think of SDTM and ADaM as two distinct stops on a data journey. SDTM is the first stop. Its entire purpose is to take the raw, sometimes messy data collected during a clinical trial and organize it into a standardized, predictable format that regulators can easily review. Think of it as creating a clean, well-cataloged library of every piece of information from the study.
ADaM is the next stop on that journey. It takes those tidy SDTM datasets and reshapes them for one specific purpose: statistical analysis. The structure of ADaM is built to make it easy for statisticians to run their models and generate results.
So, in short, SDTM is for organizing and tabulating data, while ADaM is for analyzing it. You absolutely need solid, compliant SDTM datasets before you can even begin to think about building your ADaM datasets.
How Does Controlled Terminology Fit into SDTM?
Controlled Terminology is the official dictionary for SDTM, and using it isn't optional-it's a core requirement. These are pre-defined, approved lists of terms for specific data points, and they are critical for removing any guesswork or ambiguity from the data.
For instance, the variable for a subject's sex, SEX, can't just be 'M' or 'F'. The controlled terminology dictates it must be either 'MALE' or 'FEMALE'. This ensures that every study submitted to the FDA uses the exact same language for the same concept. These vocabularies, managed by groups like CDISC and the National Cancer Institute, are what make data truly consistent and comparable across studies.
Pro Tip: Never just assume a term from your source data matches an approved controlled term. You have to validate it against the official codelists every time. For teams building automated ETL pipelines, this is where tools like the OMOPHub Python SDK become invaluable, as they can programmatically check terms against the standard vocabularies.
Can You Use SDTM for Observational Studies?
While SDTM was born out of the highly structured world of clinical trials, its principles of standardization are certainly valuable in other research areas. That said, it wasn’t designed for the wild, unpredictable nature of real-world data from sources like electronic health records (EHRs).
For large-scale observational studies, the OMOP Common Data Model (CDM) is almost always a better tool for the job. OMOP was specifically engineered to harmonize diverse and often messy data sources, making it the go-to standard for population-level research and analytics.
Accelerate your data transformation workflows with OMOPHub. Our developer-first platform provides instant API access to all OHDSI ATHENA vocabularies, eliminating the burden of managing a local database so your team can build faster and with confidence. Find out more at https://omphub.com.


