A Developer Guide to Healthcare Interoperability Solutions

Healthcare interoperability solutions are the connective tissue of modern medicine. They’re the technologies and standards that let different health information systems talk to each other and, more importantly, understand each other. Think of them as the universal translators for healthcare, making sure a patient's story remains coherent, whether it's told by a GP's electronic health record (EHR) or a specialist's imaging software across town.
Creating a Digital Nervous System for Patient Care
In nearly every other industry, we take for granted that information flows freely. Yet healthcare has been a stubborn holdout. For decades, critical patient data has been locked away in digital silos-one system for the hospital, another for the pharmacy, and a completely different one for the diagnostic lab.
This fragmentation isn't just an inconvenience; it creates real risks. It can lead to redundant tests, dangerous medical errors, and a mountain of administrative work that gets in the way of actual care.
Interoperability solutions are built to tear down these walls. They establish a "digital nervous system" that connects these isolated points of care, allowing vital information to travel securely and instantly wherever it's needed. The real goal isn’t just to send a file from A to B. It’s to make sure the data arrives in a way that’s immediately understandable and clinically useful to the person on the other end.
This model shows how true interoperability is built in layers, starting with the foundational ability to connect and moving all the way up to shared meaning and trust between organizations.
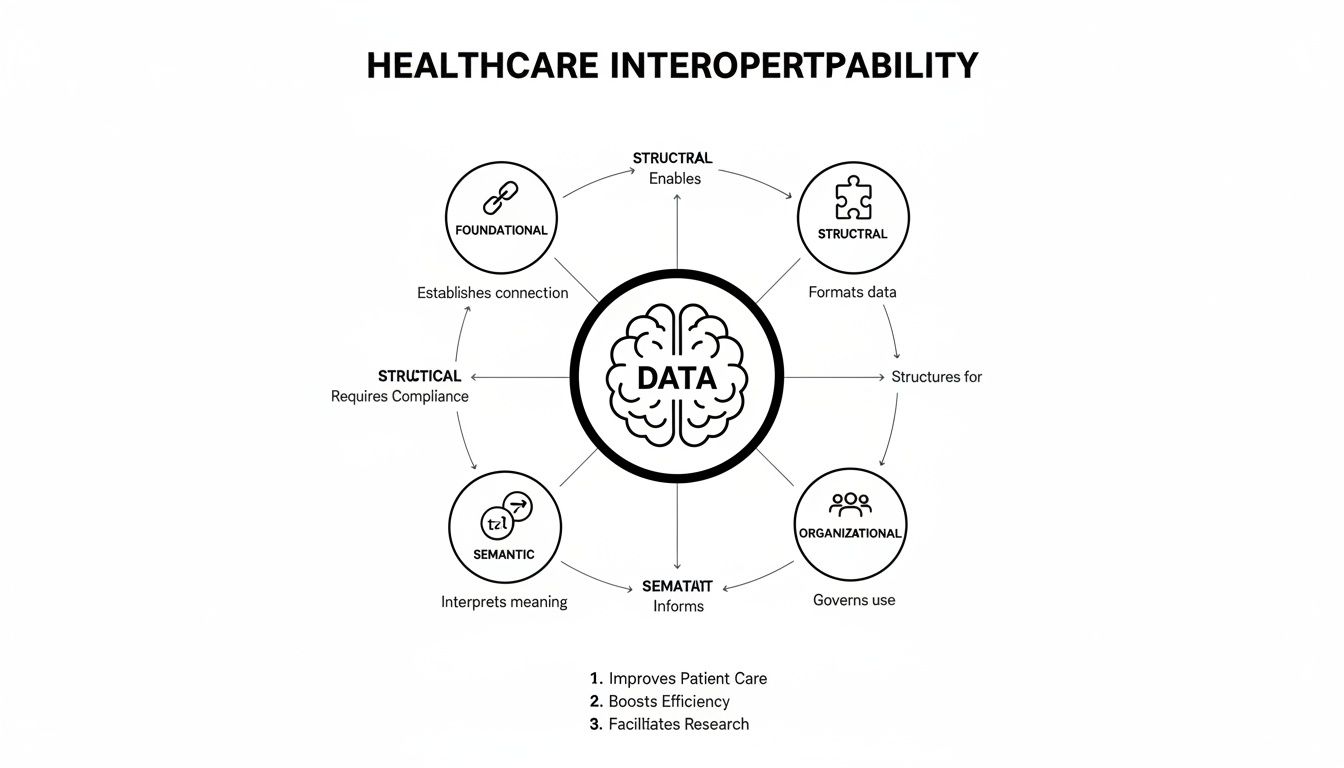
As you can see, it's a step-by-step process. You can't achieve the higher levels of coordination without getting the fundamentals right first.
The Four Levels of Healthcare Interoperability
To really get a handle on how this works, it helps to break interoperability down into four distinct levels. Each one builds on the one before it, moving from a simple digital handshake to a deep, meaningful conversation between systems.
Here’s a quick breakdown of what each level accomplishes.
| Level | Core Function | Example |
|---|---|---|
| Foundational | Establishes a secure pipe for data to travel from one system to another. | A hospital securely sends a patient's discharge summary PDF to a primary care physician's office via a direct messaging service. |
| Structural | Defines a common format or syntax for the data, so the receiving system can at least parse the information. | The discharge summary is sent as an HL7 message, so the receiving EHR can automatically place patient name, date of birth, and medications into the correct data fields. |
| Semantic | Ensures both systems share a common understanding of the data's meaning, using standardized codes. | The diagnosis in the summary is coded as "I21.3" (STEMI), which the receiving system understands means ST elevation myocardial infarction, not just text. |
| Organizational | Involves the governance, policies, and trust agreements that allow data sharing across different entities. | Two hospital networks sign a data sharing agreement under the Trusted Exchange Framework and Common Agreement (TEFCA), allowing their clinicians to query and retrieve patient records from each other's systems. |
Each level solves a different piece of the puzzle, and you need all four for the system to work seamlessly.
The push for this level of connectivity is no longer just a "nice-to-have." It's a massive business driver. The global market for healthcare interoperability solutions was valued at USD 4.27 billion in 2024 and is expected to more than double, reaching USD 9.74 billion by 2032. As this growth shows, the industry now sees interoperability not as a compliance chore, but as a core strategy for survival and success. You can explore more market growth insights from Verified Market Research.
The Language of Health Data: Standards and Terminologies
To get different healthcare systems talking to each other, they need a common language. This isn't just a figure of speech; it's a technical reality built on two key components. First, you have standards, which are the grammatical rules for structuring data. Then, you have terminologies, which act as the shared vocabulary. Think of it this way: grammar tells you how to build a sentence, while vocabulary gives you the words to use. Both are essential for creating a message that can be clearly understood.
Without this foundation, data sharing becomes a mess. One hospital's system might record "Type II Diabetes," while another logs it as "Diabetes Mellitus, Non-Insulin Dependent." Are they the same thing? A human knows they are, but a computer won't unless it has a standard way to interpret them. This is where the right standards and terminologies come in, preventing dangerous confusion and ensuring data is not just movable, but actually meaningful.
This isn't just a theoretical problem for IT teams anymore. It's a deal-breaker. In fact, a staggering 92% of hospitals in the most advanced markets now list FHIR and API capabilities as a top-three priority when buying new software. Interoperability has officially moved from a "nice-to-have" to a non-negotiable requirement.
Data Structure Standards: The Grammar
Structural standards are all about format and sequence. They provide the blueprint for a data message, telling a receiving system exactly how to read the information it receives. They dictate where to find the patient ID, the clinical observation, and the test result-much like grammar dictates the placement of a subject, verb, and object in a sentence.
Here are the three most common structural standards you'll encounter:
-
HL7 v2 (Health Level Seven Version 2): This has been the undisputed workhorse of healthcare for decades. It's an event-based messaging standard, perfect for sending real-time updates like a patient admission notification or a new lab result from a lab information system to an electronic health record.
-
CDA (Clinical Document Architecture): Another standard from HL7, CDA focuses on the structure of entire clinical documents like discharge summaries or referral letters. It bundles a patient's story into a single package that is both human-readable and machine-processable.
-
FHIR (Fast Healthcare Interoperability Resources): FHIR is the modern, web-friendly standard designed for the age of APIs. It breaks down complex health information into discrete, manageable chunks called "Resources"-like a Patient, an Observation, or a Medication. This modular approach makes it incredibly flexible and ideal for everything from mobile health apps to on-demand data queries.
Semantic Terminologies: The Vocabulary
If standards are the grammar, terminologies are the words themselves. These are massive, controlled dictionaries that assign a unique code to every possible clinical concept, from a diagnosis to a lab test to a medication. This is what allows two systems to agree that code 250.00 means the exact same thing.
A few of the most critical terminologies include:
-
SNOMED CT: The global standard for clinical terms, covering everything from symptoms and diagnoses to procedures. It ensures that a myocardial infarction is understood as the same condition everywhere, no matter the local language or phrasing.
-
LOINC: This is the go-to vocabulary for laboratory tests and clinical observations. It’s what allows a "serum glucose test" from one lab to be correctly identified and trended by any other system that receives the result.
-
RxNorm: A standardized naming system that untangles the web of brand names, generic names, and dosage forms for medications. It connects them all back to a single, consistent drug concept.
Keeping up with these terminologies is a monumental task. They are constantly updated with new codes and retired concepts, and managing these changes is a full-time job for many development teams. This is precisely why API-based terminology services have become so valuable-they handle the complexity of sourcing and versioning, giving developers a reliable, always-current source. You can dive deeper into this challenge by reading about vocabulary versioning practices.
Core Integration Architectures for Developers
Knowing the standards and terminologies is just the first half of the battle. The other, arguably more critical half, is picking the right architectural blueprint to bring it all together. For any developer tasked with building a healthcare solution, this choice comes down to the problem you're trying to solve.
There’s no magic bullet here. Instead, you have a toolbox of integration patterns, and each one has its own sweet spot. Getting it wrong can leave you with a brittle, inefficient system that’s a nightmare to maintain. But when you match the right pattern to the right use case, you build a foundation that’s both resilient and ready to scale. Let’s break down the three workhorses of healthcare integration: APIs, messaging, and ETL.
APIs for On-Demand Data Access
Modern healthcare apps-whether for patients or providers-are all about getting specific information, right now. Think of a patient pulling up their medication list on their phone or a doctor needing the latest lab results without wading through a full chart. This is where a RESTful API, especially one built on the FHIR standard, shines.
APIs work like a precise request-and-response system. A client application asks for a specific "Resource," like a FHIR Patient or Observation, and the server sends back just that piece of data, neatly packaged in JSON. It's a lightweight and flexible approach that’s tailor-made for the web and mobile world, where speed and efficiency are everything.
This on-demand model lets you build interactive tools that deliver the exact information a clinician or patient needs, at the moment they need it. It’s the difference between asking a librarian for a specific book and having them dump the entire library on your desk.
Messaging for Event-Driven Workflows
While APIs are great at pulling data, so many clinical workflows are about pushing it. Key events happen in a hospital every second-a patient is admitted, a lab order is placed, a result is ready-and these events need to trigger actions in other systems immediately.
This is the classic domain of event-driven messaging, a pattern where the HL7v2 standard has been the undisputed king for decades. When a hospital's primary system registers an "Admit, Discharge, Transfer" (ADT) event, it broadcasts an HL7v2 message. Downstream systems, from billing to labs, are always listening for these messages and react instantly. This architecture is built for real-time, asynchronous communication, ensuring critical updates ripple through the ecosystem without anyone having to ask.
ETL Pipelines for Analytics and Warehousing
Sometimes, the goal isn’t a real-time transaction but aggregating massive datasets for research, analytics, or population health management. To do that, you need an Extract, Transform, Load (ETL) pipeline. This pattern is all about pulling data from disparate sources (like multiple EHRs), transforming it into a consistent format (like the OMOP Common Data Model), and loading it into a central data warehouse.
ETL is a batch-oriented process, often running nightly, to build the comprehensive datasets needed for big-picture analysis. The "Transform" step is where the real magic-and the real work-happens. It involves complex terminology mapping to standardize local codes, a process we’ll dig into later. This is where having the right tools to streamline vocabulary access is a game-changer. For example, the recent release of the OMOPHub SDK v1.3.0 introduces powerful new features designed to dramatically speed up these transformation workflows.
Building Vocabulary Services with OMOPHub
Once you've settled on the right integration architecture, you'll inevitably face the next big challenge: the complex language of healthcare itself. Managing, updating, and querying massive terminology databases like SNOMED CT or LOINC is a heavy lift. It's a significant engineering problem that can easily drain resources and stall your development timeline.
This is exactly where a managed vocabulary service becomes a game-changer.
Instead of getting bogged down building this infrastructure from the ground up, you can lean on an API-first platform like OMOPHub. This approach takes the burden of database management, version control, and performance tuning off your team’s shoulders. The result? Your engineers can focus on solving the actual clinical data problems, not on becoming database administrators.
By integrating a simple SDK, you can get programmatic access to dozens of up-to-date terminologies and start building sophisticated mapping logic in minutes, not months.

This is the modern reality for engineering teams-they integrate powerful SDKs, like the one from OMOPHub, to add advanced vocabulary features into their applications without reinventing the wheel.
Finding Standard Concepts with Python
One of the most fundamental tasks in any healthcare data project is standardization. Let’s say your source data has a text description like "Type 2 diabetes." For that information to be truly interoperable, you need to map it to a standard concept ID from a controlled vocabulary like SNOMED CT.
Using the OMOPHub Python SDK, what used to be a complex database lookup becomes a simple API call. The code below shows just how easy it is to search for "Type 2 diabetes mellitus" and pinpoint its official SNOMED CT concept.
Pro Tip: Always set your API key as an environment variable (
OMOPHUB_API_KEY) rather than hardcoding it. This is a crucial security best practice to prevent accidentally exposing your credentials in source control.
import os
from omophub.client import Client
# Initialize the client with your API key from environment variables
# For more on authentication, see: https://docs.omophub.com/introduction/authentication
client = Client(api_key=os.environ.get("OMOPHUB_API_KEY"))
# Search for a clinical concept
try:
response = client.vocabulary.search_concepts(
query="Type 2 diabetes mellitus",
vocabulary_id=["SNOMED"],
concept_class_id=["Clinical Finding"],
limit=1
)
if response.concepts:
top_result = response.concepts[0]
print(f"Found Concept: {top_result.concept_name}")
print(f"SNOMED CT ID: {top_result.concept_id}")
print(f"Vocabulary: {top_result.vocabulary_id}")
else:
print("No matching concept found.")
except Exception as e:
print(f"An error occurred: {e}")
With just a few lines of Python, this code connects to the OMOPHub API and runs a highly targeted search. You get semantic standardization without ever having to write a complex SQL query or manage a local database. That’s the power of a managed service. For a deeper dive into search parameters, check out the official OMOPHub API documentation.
Mapping Local Codes to Standard Terminologies
Another common headache is translating proprietary, or "local," codes into standard ones. Imagine an internal lab system uses the code GLUC-PL-FAST for a fasting plasma glucose test. Before you can share that result with an external partner, it has to be mapped to its standard LOINC equivalent.
The OMOPHub API makes this translation work much simpler by letting you query the relationships between concepts. In this next example, we'll find the standard LOINC code that maps to a fictional proprietary code, assuming that relationship is defined in the vocabulary.
import os
from omophub.client import Client
# Assume our proprietary code 'GLUC-PL-FAST' has been mapped
# to a source concept with ID 90000001
SOURCE_CONCEPT_ID = 90000001
client = Client(api_key=os.environ.get("OMOPHUB_API_KEY"))
try:
# Find concepts that this source concept maps to.
# See relationship concepts here: https://docs.omophub.com/vocabulary/relationships
response = client.vocabulary.find_concept_relationships(
concept_id=SOURCE_CONCEPT_ID,
relationship_id=["Maps to"]
)
# Filter for the standard LOINC concept
found = False
for rel in response.relationships:
if rel.concept_id_2_details.vocabulary_id == "LOINC" and rel.concept_id_2_details.standard_concept == "S":
print(f"Proprietary Concept ID {SOURCE_CONCEPT_ID} maps to:")
print(f" LOINC Code: {rel.concept_id_2_details.concept_code}")
print(f" LOINC Name: {rel.concept_id_2_details.concept_name}")
found = True
break
if not found:
print(f"No standard LOINC 'Maps to' relationship found for concept {SOURCE_CONCEPT_ID}.")
except Exception as e:
print(f"An error occurred: {e}")
By programmatically walking through these relationships, you can build automated ETL pipelines that reliably translate millions of source codes into their standard forms. This is a foundational step for any serious data analytics or research project.
Using a managed vocabulary API shifts the developer's focus from infrastructure maintenance to value creation. You spend less time worrying about database updates and uptime and more time building features that directly improve data quality and clinical workflows.
This "buy vs. build" decision has a massive impact, especially for teams needing to deliver secure, high-quality solutions quickly. The differences become pretty stark when you compare the two approaches side-by-side.
OMOPHub API vs Self-Hosting Vocabularies
| Feature | OMOPHub (Managed API) | Self-Hosted Database |
|---|---|---|
| Setup Time | Minutes (install SDK, add API key) | Days or weeks (provision server, install DB, load vocabularies) |
| Maintenance | Zero; updates are managed automatically. | High; requires ongoing patching, versioning, and DBA resources. |
| Performance | Optimized for speed with global edge caching. | Dependent on local hardware and configuration; can be slow. |
| Security | Built-in compliance features like audit trails and encryption. | Responsibility of the internal team; requires significant effort. |
| Scalability | Scales automatically to handle high-volume requests. | Requires manual scaling of infrastructure, which can be costly. |
Ultimately, using a dedicated vocabulary service is a strategic move that pays dividends in both the speed and reliability of your healthcare solutions. It lets your developers integrate clean, standardized data into applications without forcing them to become experts in database administration.
Navigating Security and Regulatory Compliance
Moving sensitive patient data around is the whole point of interoperability, but it also comes with a staggering amount of responsibility. Security can't be a feature you bolt on at the end; it has to be part of the foundation, built into every decision you make from the start. This means turning dense legal regulations into real, functional safeguards within your software.
For anyone building these systems, this is far more than a compliance checklist. It's about architecting systems that are inherently secure, where patient privacy is the default setting. The stakes couldn't be higher-one mistake can shatter patient trust and lead to crippling financial and legal trouble.
Turning Regulations into Technical Guardrails
Laws like the Health Insurance Portability and Accountability Act (HIPAA) in the U.S. and Europe's General Data Protection Regulation (GDPR) lay down the law. They can feel like impenetrable legal texts, but for a developer, they break down into a few core technical principles you absolutely have to get right.
Think of it as a three-layered defense for any Protected Health Information (PHI) you handle:
- Data Encryption: All data needs to be scrambled, both while it's moving between systems (in transit) and when it's just sitting in a database (at rest). This is non-negotiable. If data is ever intercepted, it has to be completely unreadable.
- Access Control: Not everyone gets to see everything. Role-Based Access Control (RBAC) is the key here. It’s all about enforcing the "principle of least privilege," meaning people can only access the bare minimum data they need to do their jobs, and nothing more.
- Auditing: You must log every single thing that happens to patient data. Every time it's viewed, queried, or changed, it needs to be recorded in an immutable audit trail. This creates a permanent, tamper-proof history that's crucial for investigating incidents and proving compliance.
Architecting for Data Protection
Putting these ideas into practice takes careful planning. Let's say you're building an API to share patient data. Just slapping an API key on the endpoint isn't nearly enough. You have to think about how you're going to log every request, capturing who made it, what they looked at, and precisely when it happened.
A common headache is just managing the sheer volume of audit logs, which you often have to keep for years. A pro-tip here is to stream these logs directly to a dedicated, secure storage service built for long-term, unchangeable data retention.
Trying to build a fully compliant solution from the ground up is a monumental effort. That's why many teams choose platforms that are already compliant by design. It offloads a huge part of the security and auditing burden, letting them focus on what their application actually does.
For example, using a platform like OMOPHub means every API call is automatically logged into a detailed audit trail that's kept for seven years, helping you meet HIPAA rules right out of the box. Choosing tools with built-in compliance doesn't just speed up development; it dramatically lowers your security risk from day one.
Developing a Practical Interoperability Strategy
Building effective healthcare interoperability solutions is less about raw technical skill and more about having a smart, business-driven strategy. A successful project never starts with code. It starts with a well-defined use case that can deliver real, measurable value-and fast. Trying to solve every single data-sharing problem at once is a classic recipe for failure.
The smarter move is a phased, iterative approach. Pinpoint a single, high-impact workflow that's currently broken, clunky, or just plain inefficient. Maybe it's automating the way lab results get to a partner clinic, or perhaps it's streamlining the patient intake process from a referring physician's office. A tight focus like this gives you clarity and helps build crucial momentum for the bigger picture.
An effective interoperability strategy isn't about connecting everything to everything. It's about making the right connections that solve a specific business problem, prove value, and create a scalable foundation for the future.
Once you’ve locked in your use case, the real work begins with a thorough analysis of the data sources. You have to get your hands dirty. Understanding the format, quality, and terminologies of the source data is what will ultimately guide your choice of standards and architecture.
Designing a Scalable Framework
With a clear goal and a deep understanding of your data, you can finally start making those key architectural decisions. This is where you select the right tools for the job-like FHIR for modern, API-driven access or the workhorse HL7v2 for traditional, event-based messaging-that best fit the workflow you’re trying to fix.
Don’t forget about data governance. This needs to be baked in from day one, not bolted on as an afterthought. You need to define clear ownership, establish rules for data quality, and design for scale. A solution that works perfectly for one partner clinic must be robust enough to support twenty without needing a complete overhaul.
Think through these key considerations for your framework:
- Data Source Analysis: Profile every system you need to connect. What standards do they already support, if any? How clean is the data, really?
- Architectural Pattern Selection: Choose an integration pattern-API, messaging, ETL-that actually matches the speed, volume, and timing requirements of your use case.
- Scalability Planning: Always design for growth. Your solution must be able to handle more data and more connections down the line without buckling under the pressure.
Evaluating Third-Party Tools and APIs
Let's be realistic: building everything from scratch is rarely the most efficient path. The market is full of third-party tools and platforms that can give you a massive head start, but you have to evaluate them carefully. Look past the slick marketing and focus on what really matters.
Here's a practical framework for evaluating any potential tool or partner:
- Performance and Reliability: Can the service meet your latency and uptime needs? Demand proof. Look for public status pages and transparent performance metrics.
- Documentation Quality: This is a big one. Is the documentation clear, thorough, and full of practical examples? The detailed guides and code snippets you’ll find in the OMOPHub documentation are a great example of what to look for.
- Security and Compliance Posture: Does the vendor openly share information about their security controls and compliance certifications, especially HIPAA? If they're cagey about it, that's a red flag.
- Developer Experience: How quickly can your team get up and running? A well-designed SDK, like the OMOPHub Python SDK, can be the difference between a project taking weeks versus months.
By following this kind of structured approach, you can create a practical roadmap that delivers immediate wins while building a strong foundation for your long-term healthcare interoperability solutions.
Frequently Asked Questions
Getting started with healthcare interoperability can feel like learning a new language. You'll run into a lot of acronyms and concepts that might seem confusing at first. Let's break down some of the most common questions that pop up for developers and project leaders.
What Is the Difference Between HL7 v2 and FHIR?
Think of HL7 v2 as the original workhorse of healthcare messaging. It’s been around since the 1980s and is still the engine behind a huge amount of data exchange, like when your doctor’s office sends an order to a lab. It works by pushing messages between systems in a rigid, pipe-and-hat format.
FHIR (Fast Healthcare Interoperability Resources), on the other hand, is the modern, web-native approach. It uses the same RESTful APIs that power today's web and mobile apps, with data structured in familiar JSON or XML. Instead of just pushing messages, FHIR is resource-oriented, meaning a developer can simply ask for a specific piece of data-like a patient's latest lab result-and get just that piece back. It’s built for the on-demand world.
Why Are Standard Terminologies Like SNOMED CT Important?
Standard terminologies are all about making sure everyone is speaking the same clinical language. Without them, you have a data version of the Tower of Babel.
Imagine one hospital system records a diagnosis as "heart attack," while another down the street uses the more formal "myocardial infarction." To a computer, those are two different things. SNOMED CT solves this by providing a single, universal code for that specific clinical idea. This ensures that when data is shared for research or patient care, everyone understands exactly what's being discussed. It’s the foundation for true semantic interoperability.
How Does OMOPHub Help with ETL for the OMOP CDM?
Moving raw healthcare data into the OMOP Common Data Model (CDM) is a heavy lift, and one of the biggest challenges is the ETL process-specifically, mapping all your local codes to the standard OMOP vocabularies. This is where OMOPHub really simplifies things.
Traditionally, you'd have to download and manage the massive ATHENA vocabulary database yourself. With OMOPHub, you can just call its API. Your ETL script can send a local code (like an internal drug ID or an old ICD-9 code) and instantly get back the correct standard concept ID from RxNorm or SNOMED. You can even plug this directly into your code using tools like the OMOPHub Python SDK.
By turning vocabulary mapping into a simple API call, you automate a tedious and error-prone step. Your vocabularies are always current with the latest ATHENA release, which means you can build reliable data pipelines much, much faster.
Ready to accelerate your healthcare data projects with developer-first vocabulary access? With OMOPHub, you can skip the infrastructure headache of managing huge terminology databases and start building powerful, interoperable solutions in minutes. Explore our API and get started today at https://omophub.com.


